NLA - Introduction
Background
Aim of this paper
Overview
![[To top/bottom of page]](../z_designs/nav-dnup.gif) Background
Background
The SEAS White Paper [Gardner-1] stated a number of problems with IBM's software and hardware products
when they were used in countries outside the US.
The value of this paper from 1985 is that it recognized the problems, not as isolated national problems but as a set of international problems. For a better understanding of the proposed architecture these problems are summarized here, because they still exist.
Aim of this paper
This paper specifies requirements for a National Language Architecture (NLA). The purpose of this architecture is:
- To specify the services needed to create National Language Support.
- To provide application developers National Language functions that must be common to all applications.
The goal of the implementation of the proposed National Language Architecture is twofold: to allow end-users to work transparently with their natural language, and to allow application developers to implement applications independent of the culture and language of the end-users.
Hence this paper addresses two types of readers:
- People responsible for IS solutions for end-users. The paper summarises in the first part their negative experience with existing «solutions» and expresses the need for a fundamental change in the behaviour of applications.
- Application and systems programmers (in particular IBM) creating and supporting applications. The paper specifies the building blocks to make applications independent of character set, coding and culture.
The elements defined in this paper are essential for an implementation of any operating system or application, that aims for «National Language Support». In particular it is vital for the success of IBM's SAA (System Application Architecture) to implement these requirements coherently on all SAA platforms.
It was clearly stated in [Gardner-1] that an architected approach solving the many problems in the area of National Language Support is required, rather than a piecemeal solution. This paper presents SHARE Europe's view of the areas that must be covered by a National Language Architecture:
- Language (the natural language spoken and written)
- Country customs (culture-sensitive functions)
- Data encoding
- Presentation services
Although this paper only deals with languages based on the Latin alphabet and written from left to right, other languages and writing systems must also be supported by a complete NLA [Apple].
When IBM announced SAA in 1987 European customers very soon became aware that National Language Support was not addressed in SAA. This deficiency was especially discussed in the SHARE Europe Office Systems Project. Alain LaBonté and Jean-Pierre Cabanié wrote a paper about problems of sorting and searching and methods that could be used to resolve these. This requirement subsequently became known as the Davos Requirement, because it was issued at the SEAS Spring Meeting 1988, in Davos, Switzerland.
However, it was felt that the development of isolated requirements was not the best way to influence IBM to provide an architected approach as requested in [Gardner-1].
So one Sunday in mid 1988 Klaus Daube sat down to lay out this paper. And having awakened the sleeping lion he became the chairman of the newly established Special Technical Working Group.
It was the time of the great more or less peaceful revolution in Eastern Europe, when Klaus was editing the paper. When the Berlin wall was torn down, Klaus expected the implementation of a National Language Architecture to be relatively easy compared to these developments. The next step of editing coincided with the turnover in Rumania. Klaus remembered his statement years ago, that Europe not only needs the characters for the Western languages, but also - and in the same environment - those of the Eastern European languages.
While developing this White Paper, we were very happy to have Denis Garneau from IBM as our partner. He established a dialogue both with specialists within IBM (for example from the data base area) and IBM senior management which demonstrated its willingness to support its European customer needs. This was underlined by detailed discussions between some members of the STWG and IBM National Language Technical Centre at the IBM Toronto Laboratory in February 1990.
The proposed architecture may seem to be relevant to text and document processing only. IBM, however, must resist the temptation to narrow the scope of the requirements stated here. With the increasing use of workstations, the object oriented approach of programming makes it clear that text as an object must be handled independent of its environment.
Hence the implementation of the proposed National Language Architecture is relevant to all fields of information processing, but in particular for
- networks
- operating systems
- text processing
- document processing
- data base applications
- integration of text and graphics
An implementation of the proposed architecture must observe the following points:
- While it may be desirable to make certain functions available soon on the product level, the «long run» must concentrate on implementation at the operating system level.
- When providing products with National Language Support, only a complete strategy makes sense. Hence product announcements should not be made for «isolated» applications, rather they should relate the announcements to the strategy.
Overview
This paper starts with a summary of the problems in the National Language area as presented in the SEAS White Paper of 1985. Then the elements of the needed architecture to solve the problems are presented in the following order:
- Language:
- The language used must be identified in the environment. Predefined text banks need to be established for various purposes, for example messages. Names of objects must be given in the chosen language. It is also necessary to associate language with various processes like hyphenation or checking the spelling of words. Also the set of keywords in an end-user application must depend on language.
- Functions to support national languages
- must be available not only for an application, but must also be used by system services and utilities. A basic function is the «translation» of an externally representable string of characters into a processable form. This is needed for example to build a search key or for comparison of strings. Sorting and merging are other functions which must follow special rules for national languages. Finally it must be possible to query the various attributes of text.
- Culture sensitive functions
- complement the functions for supporting the language of text. Numeric punctuation uses various patterns in different countries. Also the punctuation of currency values and the presentation of date and time call for country dependent processing. It also must be possible to perform calculations with date and time, based on an arbitrary calendar.
- Messages
- are another item needed in an NLA. A set of functions must handle both messages from system services and applications. The text must be presented in a user-selectable language, which may cause re-arrangement of variables in the text.
- Documentation
- both of the National Language Architecture and of applications must be available in machine readable form. This is to allow both selective presentation and customization by an installation.
- Encoding of character data
- is a very crucial issue in a National Language Architecture. The increasing number of characters and symbols needed by the various languages and special applications call for an evolutionary approach in this area. There must be identification of the code used. Also special functions for transformations and other purposes are needed.
- Presentation Services
- must use basic functions from the NLA. They are the tip of the iceberg of this architecture - and the end-user will judge the value of the architecture by this surface.
- Keyboards
- are related to National language functions. They must support a multilingual environment as well as the demands of various applications with rich functionality.
- Implementation considerations
- are presented in the final section. They also try to explain the architecture further by examples of data structures.
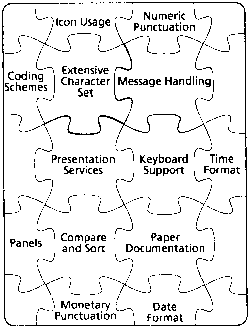
It can be seen from this overview that a National Language Architecture is a very special type of puzzle. It is not sufficient, as with a normal puzzle, to have some pieces or to have the right number of pieces. Even fitting together is not sufficient - the pieces also must be in the correct arrangement to create the image!